
這篇介紹 OpenTelemetry 的概念與應用,首先來認識一下這字「telemetry」,華文翻為遙測或遠測,維基百科有很簡短的解釋:
遠測是指傳感器在測量現場收集測量對象的數據後,數據通過無線傳輸(例如無線電、超聲波或紅外線)、電話或計算機網絡、簡訊和 GSM 等各種方式傳送至遠距離的接收設備以供監測人員監測。
簡單說就是監測,OpenTelemetry 是一套公定的監測標準,也是一套框架,用於監測應用、系統的性能指標。以粒度來看,它小到可以監測系統內每個函式的反應時間,大到可以監測一台實體或虛擬機的資源使用率,以往在跑負載測試時,我們是從外部視角去檢視應用在負載下的性能表現,但難以深入應用內部找到更具體的性能瓶頸,而 OpenTelemetry 搭配 APM 就能更好的知道自身應用具體是塞車在哪個端點,或者哪個函式。
OpenTelemetry 是一套公定標準,許多廠商以這個標準為基礎開發產品,這類產品統稱為 APM,全稱 applicatoin performance monitoring / applicatoin performance management,這類產品除了主要的性能監測外,大多還有額外的附加功能,例如通知、儀表板等,市場上 APM 產品有開源的也有閉源的,因為本篇沒有業者贊助,就不特別幫他們打廣告了,開源的選擇看來看去比較有名的(或者說 SEO 做得比較好的)有二:
個人是選用 SigNoz,理由很簡單,裝起來用看看沒什麼問題就繼續用下去,也懶得再折騰其他,雖然產品選擇眾多,但以 OpenTelemetry 為基礎的 APM 的概念都是相同的。
花式架構
由於微服務模式興起,OpenTelemetry 為了要能適用於大單體與微服務,OpenTelemetry 本身也變成能翻玩成各種花式架構的形式,一種最簡單的形式如下:
---
displayMode: compact
---
flowchart TB
app["App"]
apm["APM"]
app -- "OTLP" --> apm
我們手上的 app 直接把監測資訊打給 APM,這裡的 OTLP 是 OpenTelemetry Protocol 的縮寫,我們無須深究 OTLP 技術細節(除非你的產品就是 APM),許多語言或框架都有現成的 OpenTelemetry 整合套件可以直接使用,這部份後面會再提到。
在更實際的情境中,除了應用層的監控,我們也會想監控主機層的資源耗用狀況,為此我們需要一個專門的 collector,於是架構變成這樣:
---
displayMode: compact
---
flowchart TB
app["App"]
collector["OTel Collector"]
apm["APM"]
subgraph machine["Machine"]
app
collector
end
app -- "OTLP" --> collector -- "OTLP" --> apm
Collector 是一個獨立的程式,它會蒐集自己機身上以及別人打給它的監測資料,然後轉發出去,
Collector 是可以共用的,假設有另外一個服務跑在別人家的 serverless 平台上,我們只關心自家服務的性能,不關心底層資源的話,也可以把服務監測資訊打到另一個 collector,由一個 collector 統包,轉發給 APM:
---
displayMode: compact
---
flowchart TB
app["App"]
collector["OTel Collector"]
apm["APM"]
subgraph machine["Machine"]
app
collector
end
service["Service"]
subgraph serverless["Serverless"]
service
end
app -- "OTLP" --> collector
service -- "OTLP" --> collector
collector -- "OTLP" --> apm
至此我們認識了 OpenTelemetry 的架構以及三個主要角色:我們自己的 app、現成的 APM 產品、現成的 collector,接著我們先把現成的 APM 和 collector 裝起來,最後再把自家 app 裝上監測器。
SigNoz APM
SigNoz 是以 OpenTelemetry 為基礎的 APM,它可以以 Docker 容器或 K8s Helm Chart 的形式架設,這裡用簡單的 Docker 容器形式。
準備一台裝好 Docker 的機器,把 SigNoz Git 抓下來:
git clone -b main https://github.com/SigNoz/signoz.git它裡面有安裝腳本:
./signoz/deploy/install.sh跑起來,它會抓映像,跑容器,一波進度條跑完,SigNoz 應該就跑起來了。
假設這台機器的 IP 是 192.168.16.14,那麼 SigNoz 的網頁入口就在 http://192.168.16.14:3301,打開網頁,依照畫面指示建立一個帳號,至此 SigNoz 就裝好了。
上面的安裝腳本也附帶跑了一款範例應用 HotROD,透過這款範例應用以及它的監測資料,我們可以自由探索體驗一下 SigNoz 的功能。
在 SigNoz 的設定頁可以設定資料保存週期,可以依自己的儲存空間量與資料產生量來決定。
等到後面我們自己的應用裝設好監測,HotROD 就可以無情地拋棄了,要關掉 HotROD 也很簡單,找到 SigNoz Docker Compose 檔案,在 deploy/docker/clickhouse-setup/docker-compose.yaml,把裡面的 services.hotrod 與 services.load-hotrod 區塊註解掉,然後再跑一次安裝腳本就好:
./signoz/deploy/install.shOpenTelemetry Collector
在 OpenTelemetry 體系內,Collector 負責接收、處理、匯出資料。
Collector 安裝形式也是多元的,這裡我們以系統套件方式安裝,打包好的 OpenTelemetry Collector 系統套件可以在它的 GitHub 專案頁面下載,裡面可以看到它的包分為兩大類:
- 以 otecol 開頭,沒有 contrib 字樣。
- otecol-contrib 開頭,有 contrib 字樣。
兩者的差異在有 contrib 字樣的有另外包入一些附加元件,大部份情況下我們都選用帶 contrib 字樣的套件。
假設另一台跑 app 和 OpenTelemetry Collector 的機器是 Ubuntu,就下載 otelcol-contrib_x.y.z_linux_amd64.deb,抓完把它裝起來。
裝完之後,OpenTelemetry Collector 會成為一個系統服務,配置檔在 /etc/otelcol-contrib/config.yaml。
OpenTelemetry Collector 的配置也非常花式,甚至有點像天書,幸好 SigNoz 有提供現成的範本可以抄,把 SigNoz 提供的 Collector 配置範本抓下來,配置項目頗多,目前我們先關心如何把 Collector 收到的資料丟給 APM,找到以下區段,填入 APM 機台 IP:
exporters:
otlp:
endpoint: "<IP of machine hosting SigNoz>:4317"
tls:
insecure: true這個 exporters 區段顧名思義用於配置與輸出資料有關的項目,OpenTelemetry Collector 企圖作為資料的統包仲介,因此它被設計成模組化、可擴充的,由幾塊元件構成:
- receiver:收資料
- processor:處理資料
- exporter:輸出資料
- connector:接收與輸出資料
- extension:不經手資料的其它擴充功能
這些元件的性質大概認識就好,有需要再深入了解,它們都是可以被程式化擴充或配置的,前面裝的帶有 contrib 字樣的套件就是幫我們包好許多子元件模組的大禮包。
回頭看配置檔的 receivers 區段:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
hostmetrics:
collection_interval: 30s
scrapers:
cpu: {}
disk: {}
load: {}
filesystem: {}
memory: {}
network: {}
paging: {}
process:
mute_process_name_error: true
mute_process_exe_error: true
mute_process_io_error: true
processes: {}
prometheus:
config:
global:
scrape_interval: 30s
scrape_configs:
- job_name: otel-collector-binary
static_configs:
- targets: ['localhost:8888']可以看到,這裡配置了三種收資料的機制:
- 其一為 OTLP,讓此 Collector 監聽 4317 與 4318 埠,外部可以透過 gRPC 或 HTTP 打入 OTLP 資料。
- 其二為 hostmetrics,此乃 Collector 所在機台的硬體資源資料。
- 其三為 Prometheus 資料,Prometheus 是另一套應用監控標準,這裡 Collector 每隔三十秒會向 localhost:8888 請求數據指標(metric),這個 localhost:8888 是誰呢?就是 Collector 自己,它會在 8888 埠輸出自己的數據指標,自己跟自己要數據,而且微妙的是走的是 Prometheus,而非自己的 OTLP。
注:Prometheus 源自希臘神話,涵義為先見之明者,被用於監測機制的名字應該是取其洞察的意涵。相較於 OpenTelemetry,Prometheus 更著重於 metric,而 OpenTelemetry 著重於 trace,但兩者確有重疊,後面也會再提到什麼是 metric 與 trace。
回到配置檔主題,把改好的配置檔放到 /etc/otelcol-contrib/config.yaml,再重啟 otelcol-contrib 服務,Collector 應該就會把資料打給 APM 了。
在監測 app 前,我們先利用上面的 Host Metrics 來做機台資源儀表板。
Host Metrics 儀表板
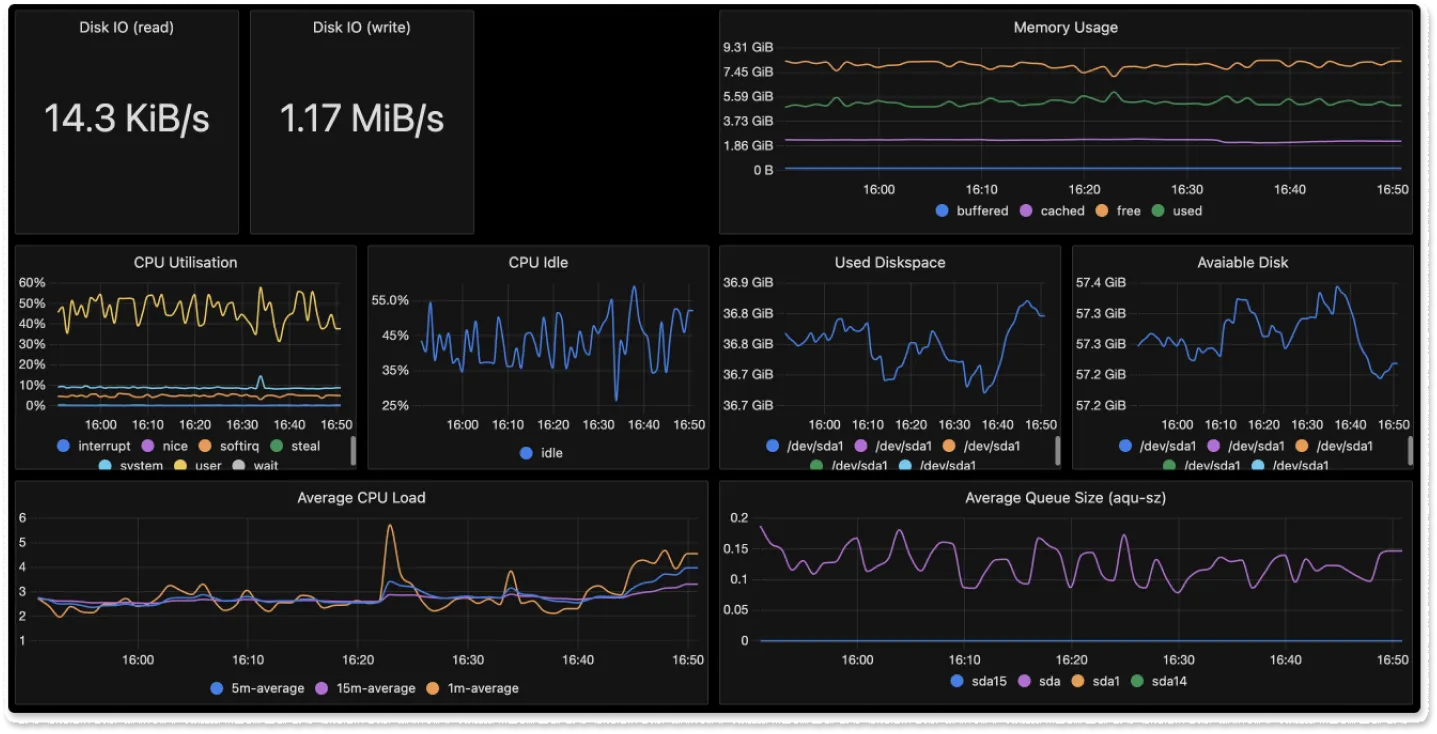
Host Metrics 為 Collector 的 receiver 模組之一,它會蒐集 Collector 所在機器的硬體資源使用狀況,前面我們配置了 CPU、記憶體等指標,SigNoz 可以根據這些數據制定一張儀表板,讓我們的 IT 戰情室看起來很厲害的感覺。
登入 SigNoz,到 Dashboard,右上角選 New Dashboard -> Import JSON,把 SigNoz 提供的 Host Metrics dashboard JSON 貼上去,收工。
這份 JSON 的結構主要由 layout 區塊與 widgets 區塊構成,layout 區塊定義的面板都有一個 UUID,widgets 定義的圖表再指定對應的 UUID,SigNoz 的佈局引擎就會根據 UUID 的對應關係排出版面與圖表,widgets 的資料來自 PromQL 的查詢結果,也支援 ClickHouse SQL 查詢,或者也可以從 SigNoz web UI 下查詢,然後保存成儀表板。
我們把貼上去的 JSON 存檔,應該就可以看到這個 Host Metrics 儀表板了,這樣就有個看起來很厲害的儀表板了,可以在老婆老闆同事面前帥一波,手寫查詢語句的部份以後有需要再深入。
真正要讓儀表版發揮功能,還要搭配 alert,例如當 CPU 衝到 90% 就通知特別冷卻戰術行動小組(S.C.S.O.F.),這時候看儀表板才有意義,不然誰會一直盯著螢幕看呢,除非你在電廠、行車調度中心、太空中心、操盤室,或 NCIS 多重威脅預警中心。
App 監測
架設完 APM 與 Collector,現在可以把我們的 app 裝上監測器了。
OpenTelemetry 已經備有多種語言與框架的監測套件,視語言或框架不同,監測器裝設方式也有不同,這裡以 Python 的 FastAPI 為例。
要監測 Python app,得先裝幾個套件:
- opentelemetry-distro,這是大禮包,內有 OpenTelemetry API、SDK、監測器等工具。
- opentelemetry-exporter-otlp,就是 Python 的 OTLP exporter 囉。
要完整安裝大禮包,得執行它附帶的安裝工具:
opentelemetry-bootstrap --action=install它會幫我們下載與安裝各個套件,這很方便,但如果在 CI 環境也想加上監測的話,也要在 CI 的配置檔執行這行指令,或是包進容器映像內。
對於 app 的開發環境與生產環境,啟動監測的方法略有不同,下面分開說明。
開發環境
開發環境下,啟動 Python app 的方式通常是跑一行指令,假設這個 app 的啟動腳本是 start-dev.py,原本的啟動命令為:
python ./start-dev.py要監測它,把啟動命令改為:
OTEL_RESOURCE_ATTRIBUTES=service.name=mocha-backend-developemnt,deployment.environment=development
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4317
OTEL_EXPORTER_OTLP_PROTOCOL=grpc
opentelemetry-instrument python ./start-dev.py第一行宣告一些關於 app 的屬性,格式為 key1=value1,key2=value2,完整的屬性清單在這裡,這邊定義了服務名、部署環境等,他們的 value 的值可以自行訂定,能清楚識別就好,前面說到 APM 可以接收多個 app 或服務的監測資料,在查詢資料時會用到這些屬性來對資料做篩選與層別。
第二行是 Collector 的位址,在上面的架構圖裡,我們把 Collector 與 app 裝在同一台機器,所以就是 localhost 囉。
最後一行的 opentelemetry-instrument 會根據前面設的環境變數發送監測資料給 Collector。
App 跑起來之後,玩一下,讓它產生點資料,等半分鐘,視角轉回 SigNoz,在 SigNoz 的 Service 與 Traces 應該可以見到 app 產生的監測資料,確認資料有成功收到。
生產環境
像上面這樣以 opentelemetry-instrument 與命令列來啟動 Python app 的方式只適用於開發環境,如果是生產環境,那啟動一款 Python web app 的方式就有各種花式可能,其中一種典型的形式是 systemd 叫起 Gunicorn,Gunicorn 叫起 Uvicorn worker 與 Python ASGI web app。
根據文件,我們要在 Gunicorn fork 行程之後才執行監測程式,這裡的 fork 是 Unix 系作業系統中一種建立行程(process)副本的機制,Gunicorn 作為 Python app server,啟動多 worker 的底層機制就是利用 fork 達成的,總之我們得在 Gunicorn 的配置檔中的一個 hook 端點 post_fork() 來執行監測程式:
# gunicorn.conf.py
from gunicorn.arbiter import Arbiter
from gunicorn.workers.base import Worker
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk import resources
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
def post_fork(server: Arbiter, worker: Worker):
server.log.info(f'Worker spawned (pid: {worker.pid})')
resource = resources.Resource.create({
resources.DEPLOYMENT_ENVIRONMENT: 'staging',
resources.SERVICE_INSTANCE_ID: 'uone_staging',
resources.SERVICE_NAME: 'uone-backend-staging',
})
span_processor = BatchSpanProcessor(OTLPSpanExporter('http://localhost:4317'))
tracer_provider = TracerProvider(resource=resource)
tracer_provider.add_span_processor(span_processor)
trace.set_tracer_provider(tracer_provider)這裡主要做兩件事:
- 建立 resource,大多是一些與前面相同的 app 屬性,改為以程式碼的形式表達罷了,讓 APM 得以篩選或層別我們關注的資料。
- 設定 tracer:
- 這裡牽涉到一個叫做 batch span processor 的東西,batch 是批次,processor 是處理器,那 span 是什麼?後面會再談到。
- Span processor 又牽涉到一個 OTLP span exporter 物件,同樣的,我們先知道它是個 OTLP 資料匯出器就好,後面再來談 span 是什麼。這裡填入 localhost,因為在前面的架構中,OpenTelemetry Collector 與 app 是裝在同一台機器內。
實際上,要從 app 直接打給 SigNoz 也可以,因為 SigNoz 也跑了個 Collector 來接受別人打給它的監測資料,我們把前面的架構圖 APM 的方塊再展開:
---
displayMode: compact
---
flowchart TB
app["App"]
ap_machine_collector["OTel Collector"]
apm_collector["OTel Collector"]
subgraph ap_machine["AP Machine"]
app
ap_machine_collector
end
subgraph apm["APM"]
apm_collector
end
app -- "OTLP" --> ap_machine_collector -- "OTLP" --> apm_collector
就可以明白 APM 也理所當然裡面有個 Collector。
另外,在 app 內部,也要呼叫監測程式,以 FastAPI 為例:
from fastapi import FastAPI, Request
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor
fastapi_app = FastAPI()
FastAPIInstrumentor.instrument_app(fastapi_app)
@app.get('/foobar')
async def foobar():
return {'message': 'hello world'}重點在多加了一句 FastAPIInstrumentor.instrument_app(),其它都是 FastAPI 原本的東西。
相較於開發環境,生產環境的監測麻煩一點,不過也還好,這些都做完之後,跑個測試,上個新版,重啟服務,進入 app 玩一下,等個半分鐘,進入 SigNoz 看看有沒有 trace 資料進來吧。
監測資料
對於 OpenTelemetry 的監測資料,前面我們僅概略的知道有什麼 trace、metric,又有 span 什麼的,在 OpenTelemetry 的概念裡,它支援三類監測資料,分別是 trace、metric、log,而 span 則是 trace 類資料裡的一種概念,為了避免越說越迷糊,下面逐一展開,從最簡單的 log 開始。
Log
雖然本文在此之前都未提及,但 OpenTelemetry 也支援收發 log,而 APM 也兼具 log server 的角色,以 Python 為例,OpenTelemetry 套件提供了與 Python 原生 logging 模組整合的 logging handler,只要把它配置一下,就如同其它的 logging handler 一樣,調用 Logger 物件的 addHander() 方法,把 OpenTelemetry logging handler 餵入即可,參考以下範例:
import logging
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.sdk._logs import LoggingHandler, LoggerProvider
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk import resources
resource = resource = resources.Resource.create({
resources.DEPLOYMENT_ENVIRONMENT: 'staging',
resources.SERVICE_INSTANCE_ID: 'uone_staging',
resources.SERVICE_NAME: 'uone-backend-staging',
})
logger_provider = LoggerProvider(resource)
set_logger_provider(logger_provider)
log_record_processor = BatchLogRecordProcessor(
OTLPLogExporter('http://localhost:4317', insecure=True)
)
logger_provider.add_log_record_processor(log_record_processor)
handler = LoggingHandler(logger_provider=logger_provider)
# Attach OTLP handler to root logger
logging.getLogger().addHandler(handler)
# Log directly
logging.info("Jackdaws love my big sphinx of quartz.")這裡和前面設定 trace 有八成像,同樣的 resource、類似的 processor、類似的 set logger provider,主要差別在最後要記得呼叫 addHandler()。
Metric
Metric 一般翻為指標或數據指標,總之就是一系列量值,例如前面 Host Metrics 見過的記憶體使用率、CPU 使用率等等,除了像這些由既有模組制定好的 metric 外,我們也可以制定自己關心的 metric,例如登入錯誤的次數等等,再搭配儀表板與警示就可以即時通知人員介入處理,更多說明可以參考 OpenTelemetry 文件。
Trace
Trace 指的是一次請求的鏈路軌跡,一個 trace 由帶有父子關係的 span 構成,例如一個公開的 API 端點 /foobar,它的處理函式 foobar() 裡面呼叫了 baz(),那就會形成由一組巢狀 span 構成的 trace,其中 root span 為 foobar() 的監測資料,sub-span 為 baz() 的監測資料,監測資料內容包括處理時間、客戶端資訊、app 端資訊等,APM 方面會以端點為單位幫我們統計平均回應時間等資訊。
我們進入 SigNoz 的 Services 內頁,可以看到一些統計數據,包括 Latency、Rate、Apdex、Key Operations、Error Percentage 等: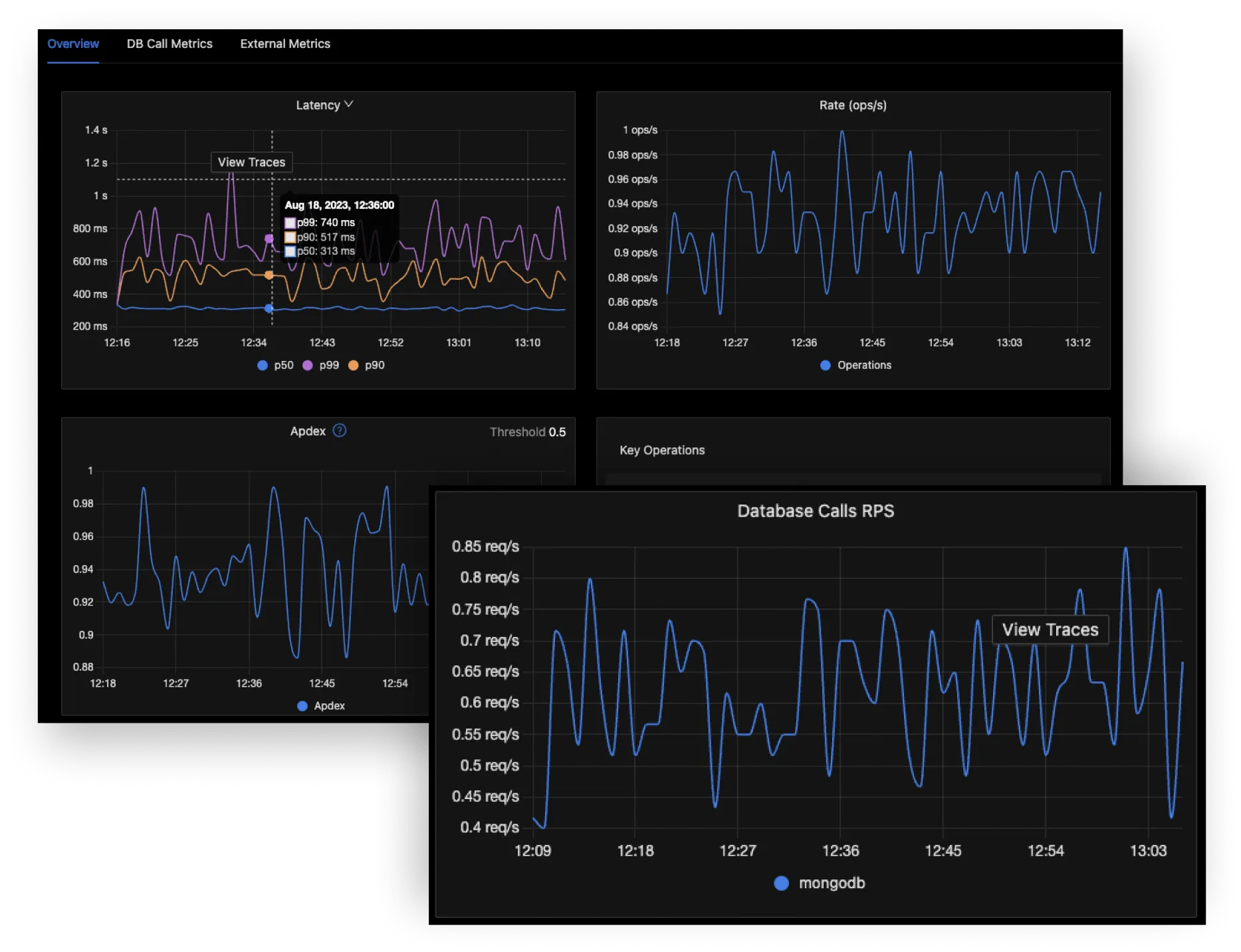
這幾項資料可以讓我們從較大的視角得知當前服務的狀態,如果要更深入看端點的反應,可以點入 Key Operation 清單中的端點,檢視單一端點的統計數據: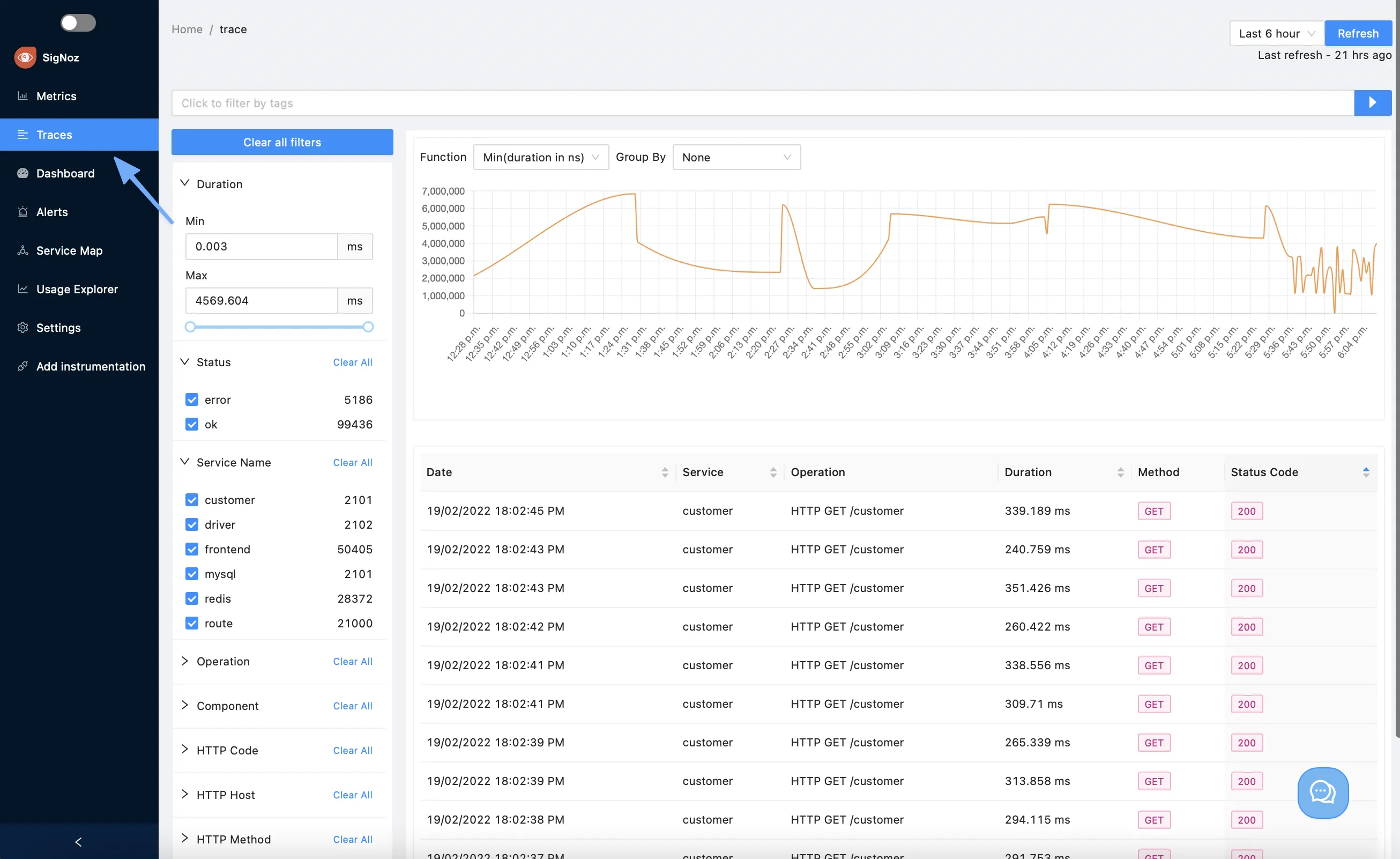
還可以再深入到單一請求的 trace,去檢視主要的性能瓶頸發生在哪個 span:

具體要怎麼運用這些監測,就看各人的需求啦。
結語
本文介紹了 OpenTelemetry 及以其為基礎的 APM SigNoz,透過這套標準與工具,我們得以從應用內部的視角即時的監控它的性能,本文著重於用最簡短的方式介紹 OpenTelemetry 概念與監測機制建置,OpenTelemetry 博大精深,Collector、trace、metric、log 都足以獨立為一篇文章,有興趣的讀者可以自行深入囉!個人是認為 OpenTelemetry 的文件太多太雜又太分散,對新手來說實在很難入門,希望這邊文章有幫助到不得其門而入的你。
另外,也有些 APM 產品是不走 OpenTelemetry 的,畢竟這類「標準」很多,有 OpenTelemetry、StatsD、Prometheus 等等,扮演 data collector 的同類工具也很多,有 OpenTelemetry Collector、Fluentd、Fluent Bit、Datadog Vector 等等,彼此都互有重疊、或有兼容、各有特色,很容易落入選擇障礙,逐套嘗試顯然不現實,在下一個大而全的新輪子被重新發明之前,選用以 OpenTelemetry 為基礎的 APM 看起來是最佳解。
Share






作者:Leon
不是五小編也不是七小編,就是六小編。

